Kris Jack, Ed Ingold and Maya Hristakeva.
Introduction
Mendeley Suggest, a personalised research literature recommender, has been live for around nine months so we thought we’d mark this traditional human gestation period with a blog post about its architecture. We’ll present how the architecture currently looks, pointing out which technologies we use, justifying decisions that we’re happy with and lamenting those that we’re eager to reconsider.
Architectural Overview
A recommender system is more than just the smart algorithms that it implements. In fact, it’s a collection of five core components that are designed to interact with one another primarily to meet a set of user needs:
- User Interface
- Data Collection and Processing
- Recommender Model
- Recommendation Post-processing
- Online Modules
In the case of Mendeley Suggest, we aim to provide users with articles that help them to keep up-to-date with research in their field and explore relevant research that is, as of yet, unknown to them. You can see, from an architectural perspective, how these five components interact with one another in Mendeley Suggest (Figure 1). Let’s delve into each component one at a time to reveal what’s going on under the hood.
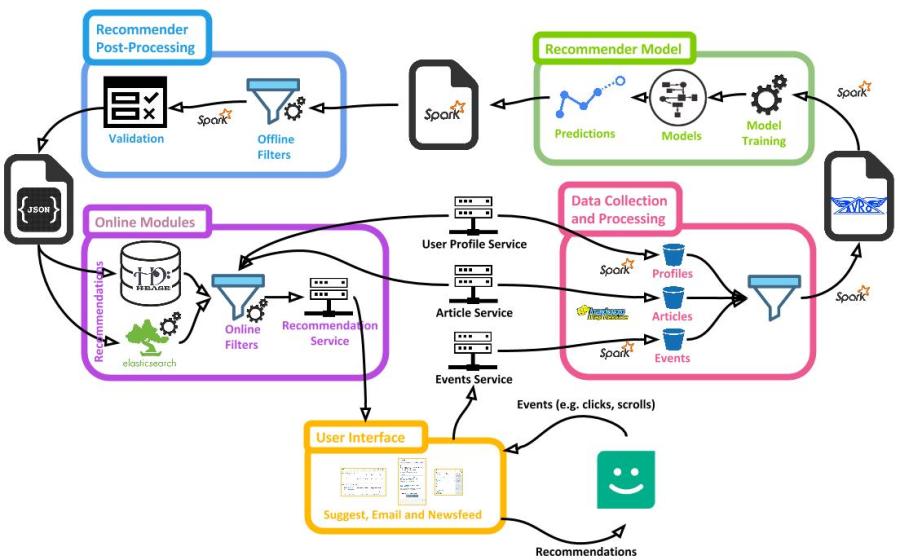
User Interface
The user interface present users with recommendations of articles that they may be interested in reading. The recommender system’s architecture is client aware but generic enough for a variety of frontends to plug into it. We currently have three clients that are live (with more on their way): Suggest portal; newsfeed; and e-mail sender.
Each of these clients have their own user interfaces, that act as the ‘faces’ of the recommender system and the most direct channels through which users interact with it. The contract between the recommender service and clients is defined through an API. When given a user’s unique profile id and context (e.g. device type, previous actions) returns an ordered list of recommended articles to serve to them. We use a JSON format, in which we return multiple resources, each of which is a RESTful entity (i.e. there is a somewhere you can GET to it). Originally, we used to return the id of articles being recommended as resources, making it the responsibility of the client to then call a centralised metadata lookup service to get the article’s metadata. Over time, however, we noticed that clients always needed the article metadata and so decided to bundle the metadata in the resource too which brought efficiency benefits.
The API returns a JSON blob with three elements: resource being recommended; explicit rank; and trace token. The resource being recommended in this case is the id and metadata of the article that may be interesting for the user to read. The explicit rank is an integer that allows the client to know the order in which the resources are expected to be of interest to the user. The client is not obliged to show the recommended resources in the order specified by the explicit rank. The trace token is a 64-bit encoded string and is unique for the request that was made. It serves an important purpose, allowing clients that consume recommendations to provide feedback, letting the recommender system know, for example, that a recommended resource was received, displayed to the user and in the viewing window of their scrollable page.
Depending upon the user interface exposed by a client, users also have a number of actions that they can perform such as adding a recommended article to their library, requesting to see more recommendations, and sharing a recommendation with other users. For a selection of user actions, the client tries to record them as events and send them back to the recommender system so that it can learn from them and improve the recommendations that it serves. When the client sends these events to the recommender system, they are relayed on to Mendeley’s main event handling service, which is built on an inherently scalable framework, where they are managed. Up until now, all of the recommender system’s functionality has been read-only. This is the only circumstance under which the recommender API allows for data to be written. Once in the event framework, analytic reports such as the CTR for served recommendations with respect to a particular client, are then straight-forward to generate.
Data Collection and Processing
Mendeley Suggest’s recommendations are generated from a variety of data sources, too many to fit in the architectural diagram (Figure 1), so we’ve simplified it to naming three important ones: the events service; user profiles service; and the research article service.
Every day we collect data from the events service. We aren’t interested in all of the events stored there, just the ones that are recommender specific. Mendeley events are processed and stored using the Amazon Kinesis Firehose. We use Elastic MapReduce to spin up a Spark cluster, that reads in events, filtering out those that are not relevant to the recommender system. The events that remain are stored in S3.
The profile service contains user profile information, such as the user’s academic discipline, that we use to personalise their recommendations. The data is extracted straight from the profile service API from another Spark job that scans through the tables and stores the results in S3.
The research article service contains over one hundred million unique research articles from Mendeley’s catalogue. It is a crowdsourced collection derived from billions of research articles that individual Mendeley users have added to their libraries throughout the world. As such, it’s also quite a noisy data set as deduplicating these records at scale is quite a challenge. Despite the noise, it’s a useful dataset and valuable input for Mendeley Suggest’s collaborative filtering algorithms. The research article service contains the metadata for these articles as well as how they are distributed throughout user libraries. The recommender system dumps the data from the research article service by running an Elastic MapReduce job over HBase and writing the results to S3.
The three data sets go through a set of filters to remove data that’s not needed by the Recommender Model and stored as avro files in S3.
Recommender Model
The component that most people focus on when thinking about a recommender system is the recommender model. This is where the data that has been collected and processed is input into the recommender, a model is trained and it generates predictions of which articles users may be interested in.
In Mendeley Suggest, all of this modelling is orchestrated via the AWS data pipeline. We’re reasonably content with the AWS pipeline as data flow orchestration is complex in production-quality systems but it’s worth mentioning a few difficulties that we have had. First, we don’t find the AWS data pipeline to be well suited for iterative development. It has unusual update semantics, limitations to the number of parameters that you can add to it and can be difficult to test in isolation. All in all, there remains a lot of inherent complexity to deal with that will hopefully be simplified over time.
The recommender model implements a number of different recommendation algorithms. The algorithms output recommendations as Spark RDDs of a generic format. A lot of this was written pre-DataFrame and it runs well so we haven’t seen the need to rewrite it yet. At present, we have algorithmic implementations of:
- Collaborative filtering. Here, we have one version that makes use of Mahout and another implemented in Spark. Both are custom implementations of user-based collaborative filtering. We go with user-based rather than item-based collaborative filtering for two main reasons. First, typically, online businesses that use recommender systems have many more users than items that can be recommended. In our case, the data is an unusual shape in that we have many hundreds of millions of items that can be recommended (i.e. all research articles ever published) and only tens of millions of users (i.e. the research community). User-based collaborative filtering scales better than item-based collaborative filtering in this case. Also, through empirical testing, we demonstrate that user-based collaborative filtering generates better quality recommendations than the item-based flavour.
- Popularity-based models. These models determine which articles are popular in Mendeley’s community. We wrote a number of custom Spark jobs that slice and dice activity data around articles in order to determine which ones are popular in which contexts (e.g. Popular articles in Computer Science/Biology).
- Trending-based models. When articles have had a significant and recent uplift in activity (i.e. there’s a buzz around them), these models pick up on it and signal them as trending. Here we have some custom time series analysis jobs implemented in Spark.
- Content-based filtering. Research articles are rich in text. We have a number of jobs that take content from research articles (e.g. title, authors, publication venue, year of publication) and prepare a data set that will be loaded into an ElasticSearch index.
These algorithms make use of many different data sources including, but not limited to, user profile data, research article data and event records. They also make use of event data in order to implement some business logic, such as, do not show the same recommendations to the same user twice in a row. Event data is processed and output by the recommender model so that it is available for use by downstream components in the pipeline.
Recommender Post-Processing
Once the raw recommendations have been generated by the Recommender Model, it’s the job of the Recommender Post Processing component to prepare them to be served by the Online Modules. In Mendeley Suggest, the raw recommendations are processed by Spark (read in as Spark RDDs) and output in a JSON format ready to be uploaded to the serving layer. Here, we do some last minute sanity checking of the recommendations and apply some business logic aimed at generally avoiding making the recommender system look stupid.
Given that the recommender system is generating hundreds of recommended articles per user, it’s impossible to manually verify the output of every model for each user. Instead, we have a set of automated sanity checks that focus on quantitative properties of the recommendations and a set of manual eye-ball checks that focus on the quality of recommendations for a small sample of users. If a model does not generate enough recommendations per user, on average, or too few users will receive recommendations then the automated sanity checks will flag this up and notify the team that there’s a problem. Manual eyeballing of recommendations is also an important part of the pipeline since bugs can be introduced that will slip through the quantitative sanity checks. If the manual verify uncovers a problem then the current pipeline’s run will not be released live. Once we track down and fix the offending bug, we then run the entire pipeline again from scratch. In the future, we’d like to be able to just rerun infected parts of the pipeline once the fix has been pushed as the current reboiling of the ocean is quite wasteful.
We also have some filtering and reranking methods that are applied at this point. For example, we typically don’t want to recommend the same list of articles to users every day. If a user has already seen a set of recommendations and not added them to their library then we use this implicit negative feedback to reduce the probability of it being shown again to them in the future, using techniques like impression discounting and dithering. Dithering adds a little noise to the ranking of the recommendations, randomly shuffling their positions around a little. In practice, this is simple form of an explore-exploit strategy allowing us to learn more about articles that have low ranking positions (according to the model predictions) as they may randomly be pushed up the list being displayed to the user. It can also have the nice side-effect of keeping the list of recommendations look new despite the fact that they may have just been hidden lower down the list and not in the user’s current view.
It’s worth pointing out that up until the point that randomness is applied to the recommendations, in processes like dithering, the system is deterministic. That is, given the same input, the recommender system will produce the same output up until this point in the pipeline. This is a nice property for the system to have, despite the complexity of the recommender models and the system as a whole.
Online Models
To close the loop in our architectural story, the last component to describe is the Online Modules. These modules take the validated recommendations produced by the Recommendation Post-processing component and upload them into the Online Modules. The Online Modules house a number of servers designed to serve recommendations to users in real-time, through the recommender service API, originally described in the section on the User Interface. The Online Modules also contain online filters similar to those applied in the Recommendation Post-Processing component, but in real-time, to account for any changes in state that occurred between the recommendations being validated and being served.
Mendeley Suggest implements a number of servers all exposed via a single recommender service API. Most recommendations are uploaded to HBase, a popular <key, value> store, where the key is the user’s profile and the value is the JSON blob with their validated recommendations. We also make use of ElasticSearch to index research article text and return recommendations that are relevant to free text interests manually entered by users. For example, if users enter that they are interested in “Deep Learning” and “Recommender Systems” in their Mendeley profile, then these terms are used to query the ElasticSearch index, which has been tuned to return relevant and trending research articles on those topics.
Regardless of whether the recommendations are served from HBase or ElasticSearch, they all need to go through online filters. These filters are very similar to the ones found in the Recommendation Post-Processing component. For example, we don’t want to recommend an article to a user if they already have it in their library. The Online Module therefore requires access to the User Profile and Research Article services to ensure that it’s not recommending them research articles that they already have. We are also able to apply impression discounting and dithering online in we want them to have a more aggressive impact. Once the recommendations are filtered they are then served through the recommender service and displayed to the user.
Conclusions
As we keep emphasising throughout this blog, a recommender system is far more than just the core recommender algorithms that it implements. We like to think of a recommender as being made up of five components of varying importance and with different responsibilities. Mendeley’s architecture cleanly separates these five components out from one another, thus making their relative responsibilities clear. The implementation is robust, allowing it to scale to massive quantities of data and to serve large volumes of traffic.

Reblogged this on Razin's Tech blog.
LikeLike