This is the third in a multi-part post. In the first post, we introduced the main types of recommender algorithms by providing a cheatsheet for them. In the second post, covered the different types of collaborative filtering algorithms highlighting some of their nuances and how they differ from one another. In this blog post, we’ll describe content-based filtering in more detail and discuss its pros and cons in order to give a deeper understanding of how it works.
Content-based filtering recommends items that are similar to the ones the user liked in the past. It differs from collaborative filtering, however, by deriving the similarity between items based on their content (e.g. title, year, description) and not how people use them. For example, if a user likes “Lord of the Rings: The Fellowship of the Ring” and “Lord of the Rings: Two Towers” then using the words in the title, the recommender may suggest “Lords of the Rings: The Return of the King”. In content-based filtering, rich information describing each item is assumed to be available in the form of a feature vector (y) (e.g. title, year, description). These feature vectors are used to create a model of the user’s preferences. A variety of information retrieval (e.g. tf-idf) and machine learning techniques (e.g. Naive Bayes, support vector machines, decision trees, etc) can be used to generate a user model based on which recommendations can be generated.
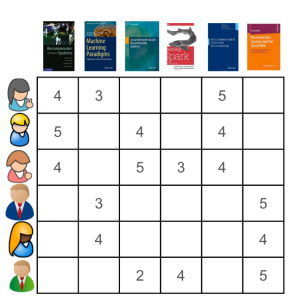
Say that we have some users who have expressed preferences for a range of books. The more that they like the book, the higher a rating they give it, from a scale of one to five. We can represent their preferences in a matrix, where the rows contain the users and the columns the books (Figure 1).
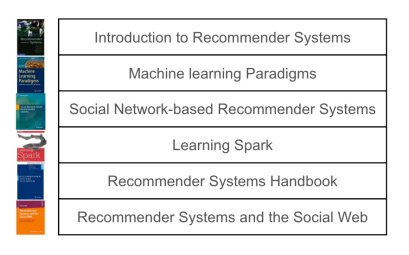
In content-based filtering, the first thing that we want to do is to calculate how similar books are to one another based on their content. In our example, we will use the words in the titles of the books (Figure 2). This is just to simplify how a content-based solution works. In practice, you would use many more attributes.
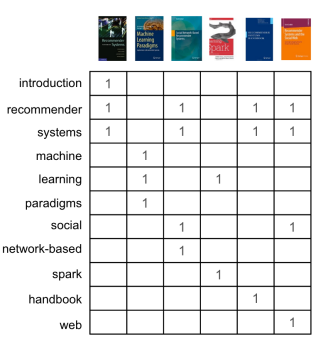
First, it’s common to remove the stop words (e.g. grammar words, very common words) from the content and then to represent the books as a vector (or array) that indicates which words are present (Figure 3). This is known as a vector-space representation.
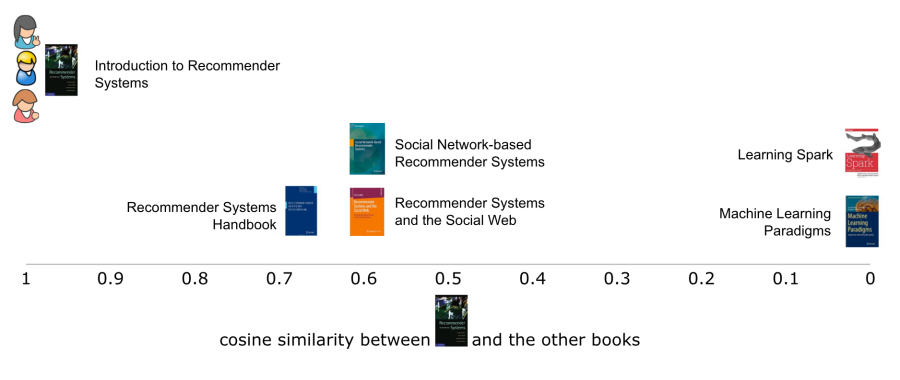
Given this representation of each book it’s quite straight-forward to compare books with one another using a variety of similarity metrics. In this example, we’re going to use cosine similarity. When we take the first book and compare them to the five other books, we can see how similar the first book is to the rest of them (Figure 4). As with most similarity metrics, the higher the similarity between vectors, the more similar they are to one another. In this case, the first book is quite similar to 3 of the books, with which it shares 2 words (recommender and systems). It is most similar to the book with fewer words, which makes sense, as it has fewer extra words not in common. It is not at all similar to the other 2 books with which it has no words in common.
More fully, we can show how similar all books are to one another in a similarity matrix (Figure 5). The background colour of the cell shows how similar two books are to one another, the darker the red, the more similar they are.
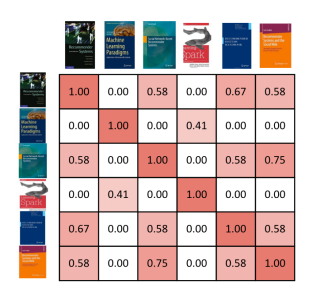
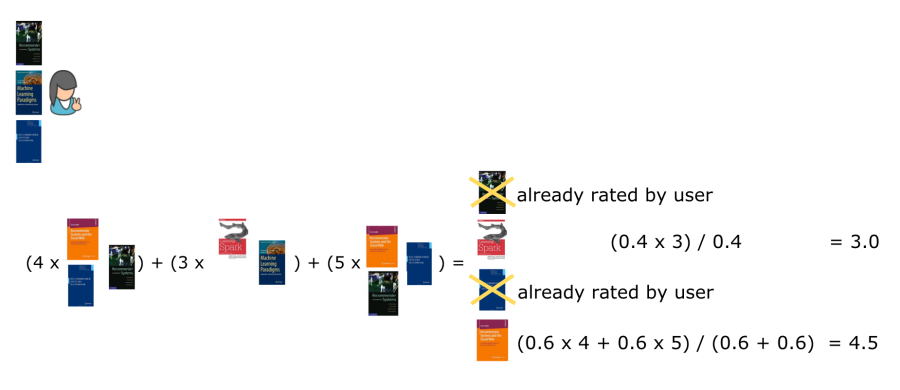
Now that we know how similar the books are to one another, we can generate recommendations for users. Similarly to the item-based CF approach we described in the previous post, we take the books that a user has previously rated, and recommend other books that are most similar to them. The difference is that here the similarity is based on the content of the books, precisely the titles, rather than on the usage data. In our example, the first user would be recommended the sixth book followed by the fourth book (Figure 6). Again, we only take the top two most similar books to the books that the user has previously rated.
Content-based approaches overcome some of the limitations of collaborative filtering. In particular, they help you to overcome the popularity bias and new item cold start problem, which we already discussed in the section on collaborative filtering. However, it is worth noting that recommenders purely based on content generally don’t perform as well as ones based on usage data (e.g. collaborative filtering). Content-based filtering also suffer from over-specialisation, where the user might get too many of the same types of items (e.g. being recommended all of the “Lord The Rings” movies) and fail to recommend items that are different but still might be interesting to the user. Finally, content-based implementations that only use the words contained in item metadata (e.g. title, description year), will tend to bring back more of the same content, which limits its usefulness for help users to explore and discover content that’s outside of that vocabulary. See Table 2 for a summary of the pros and cons of content-based filtering.

[…] of Recommender Algorithms (part 1, part 2, part 3, part 4, part […]
LikeLike
What is content based recommender system?
Content-based filtering recommends items that are similar to the ones the user liked in the past. It differs from collaborative filtering, however, by deriving the similarity between items based on their content (e.g. title, year, description) and not…
LikeLike