Choosing the right algorithm for your recommender is an important decision to make. There are a lot of algorithms available and it can be difficult to tell which one is appropriate for the problem you’re trying to solve. Each algorithm has its pros and cons as well as constraints that you would want to have a feeling for before you decide which one to use. In practice, you will probably test out several algorithms in order to discover which one works best for your users and it will help to have strong intuition about what they are and how they work.
Recommender algorithms are typically implemented in the recommender model (2), which is responsible for taking data, such as user preferences and descriptions of the items that can be recommended, and predicting which items will be of interest to a given set of users.
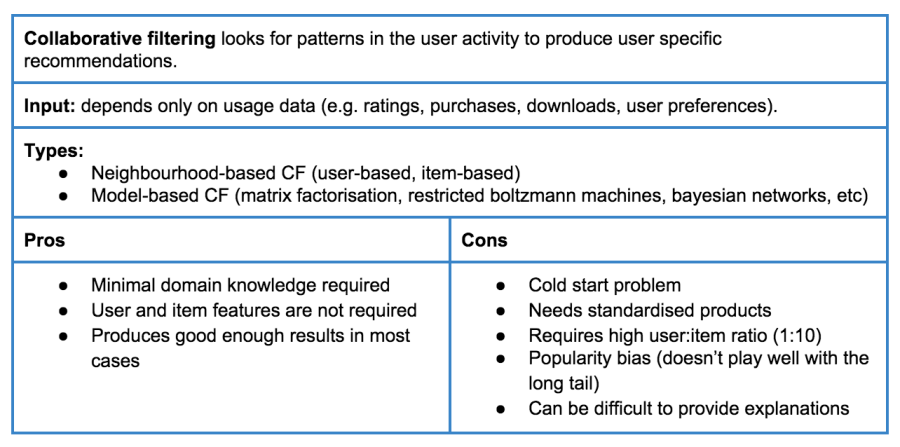
There are four main families of recommender algorithms (Tables 1-4):
- Collaborative Filtering
- Content-based Filtering
- Hybrid Approaches
- Popularity
There’s also a number of advanced or non-traditional approaches (Table 5).
This is the first in a multi-part post. In this post, we’ll introduce the main types of recommender algorithms by providing a cheatsheet for them. It includes a brief description of the algorithm, its typical input, common forms that it can take and its pros and cons. In the second and third posts, we’ll then describe the different algorithms in more detail, to give a deeper understanding for how they work. Some of the content in this blog post is based on a RecSys 2014 tutorial, The Recommender Problem Revisited, by Xavier Amatriain.





There is a danger in a list of algorithms like this. The danger is that a team who is implementing a recommender will focus on algorithmic choices to the detriment of examining the data that they might have available. The problem with focussing on algorithms is two-fold:
1) it is actually remarkably difficult to evaluate recommenders. For instance you split traffic between two recommenders, the one with the larger share of traffic will typically do better because it has more data. If you pool all the data from all of the systems being evaluated, you can have co-evolutionary effects where one algorithm performs poorly, but is critical to the success of the other algorithm because it provides a wide range of training data.
2) the second aspect is that implementing different algorithms takes time and effort and is likely to give you single digit percentage improvements. Adding new data sources, however, will often get you 2 or 3 digit percentage improvements. As such, exploring new data rather than new algorithms is almost certainly a better use of time.
Academic researchers tend to focus on new algorithms precisely because they can’t get new data and because they need well characterized problems to do repeatable research. This is a huge contrast to the situation in a commercial devops setting where spending months getting the last few percentages of improvement is typically a colossal waste of time.
LikeLiked by 3 people
[…] of Recommender Algorithms (part 1, part 2, part 3, part 4, part […]
LikeLiked by 1 person
[…] is the second in a multi-part post. In the first post, we introduced the main types of recommender algorithms by providing a cheatsheet for them. In this […]
LikeLike
[…] về các kỹ thuật cũng như ưu, nhược điểm của chúng được trình bày tại awesome post. Post này trình bày về phương pháp content-based […]
LikeLike
[…] 《Overview of Recommender Algorithms part1》 […]
LikeLike